How "good enough" AI could make voice assistants more ethical
In 2019 it was revealed that Amazon, Google and even Apple employed thousands of people to listen to voice recordings from their smart assistants. They defended this practise by saying it is necessary to improve the quality of their voice assistants. But is this really a valid argument?
To answer this question we need to first look a little closer at how 'machine learning', more popularly referred to as 'AI', works.
When has the machine learned enough?
At first glance, the companies mentioned have a fair point. As the name implies, machine learning relies on the computers themselves recognising patterns in vast amounts of training data. For example, if you show these types of algorithms a lot of pictures of cats, then after a while they will be able to tell you if a new picture you show them looks like a cat.
If you show the computer a thousand pictures of black cats, and then ask it to classify a picture of a red cat, it would likely fail. So the trick is to cover as much of the 'possibility space' beforehand. The more variety in your training data, the more robust the algorithms become. This makes training AI a 'long tail' problem: you could always discover new varieties of cats found in the wild, and then it would be wise to teach the algorithm that this too is a cat.
So in theory then, these companies have a point. The more data you have to feed your algorithm, the better.

"Good enough" AI
Where it falls apart is in practise. Even though you could still come across new and unknown versions of cats, after a while the odds of that become increasingly small.
If we drop the cats example and return to voice, it's certainly true that people invent new words. New languages and accents do develop. But how often does this happen? More importantly, even if it happens, does it affect the ability of a voice control system to operate well? If me and my friends come up with a new word for 'sailing boat', should a system designed to turn lights on and off really know about this?
The realistic answer is no. For the smart home situation, you could argue that we have long ago reached the 'good enough' stage, where the most common accents, words and intentions have all been accounted for.
Proof of this can be found by looking at the rise of a new generation of companies that offer 'cloudless' voice control.
Good enough AI as a business model: the case of Snips
![]()
For the Candle smart home we settled on using the voice control technology of a French company called Snips. We chose them because of all the options we researched they seemed to take "no internet connection required" the most seriously. On top of that they are based in Europe, and their software runs well on a low-power computer like the Raspberry Pi.
But more importantly their technology has embraced this 'good enough' stage of AI development. The reason they can offer this 'cloudless' solution (also known as 'edge computing' in the business), is precisely because they recognised that for most consumers it could offer a 'good enough' solution. Even more so if you know the situation the voice control software will be used in, and can optimise for it.
Candle is a good example of this. It allows you to use the most popular voice commands, such as:
- Setting a timer, alarm, reminder or countdown
- Asking for the time
- Switching devices on off or to a specific level
- Asking about the state and levels of devices. E.g. "What level has the thermostat been set to?".
A system like this doesn't need to understand all the words in the English language. It can forego the names of insects, the mechanical parts of an oil drill, or the names of all the political parties, and so forth. It's also less likely to run into strange grammar. There are only so many ways you can ask what time it is.
We know, because we tried:
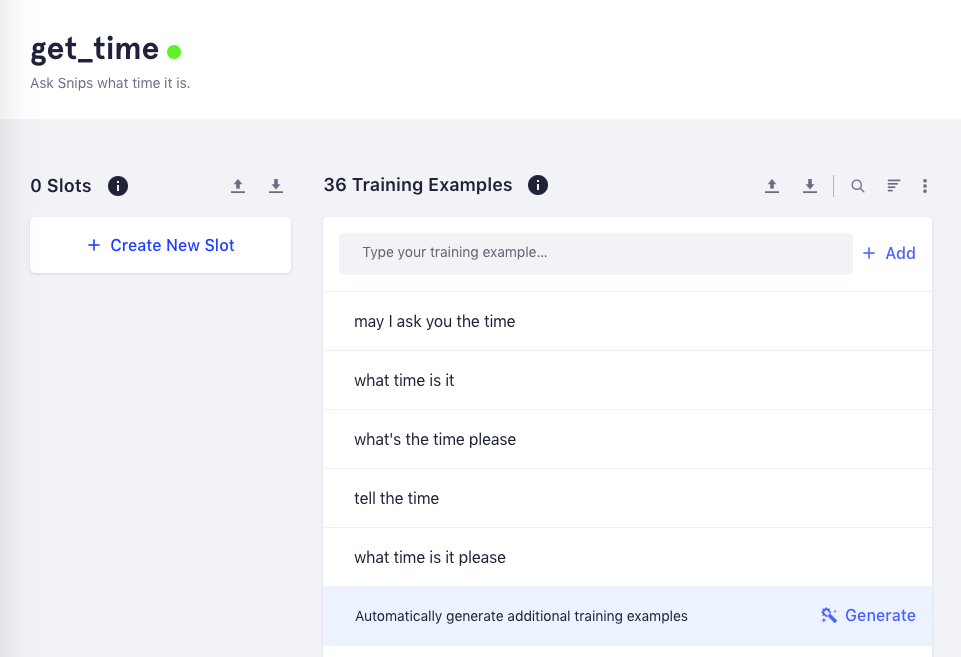
This is the Snips interface. You can train Snips to recognise new commands by feeding it lots of examples. Try coming up with 36 ways of asking for the time...
In our experience, cloudless systems like Snips, Mycroft, Picovoice and others have proven very reliable. During out tests Snips was able to recognise commands perfectly well, even if spoken by different people and in various accents.
In other words, in 2019 basic voice control feels like a solved problem.
Let consumers choose what they are comfortable with
This is why the "we need to keep training forever" argument feels a bit disingenuous. If we blindly accept this defence, as many journalists unfortunately do, then we miss out on an opportunity to discuss what people would prefer.
For example, imagine consumers were offered this choice:

Which option would you choose? Out of the box, Candle enforces the 'full privacy' option.
Don't forget, while these companies will focus on framing their need to record you as eventually being beneficial to you, this is only part of the story. Whenever your voice is used to teach the system about something new, you are doing work for them. This means these companies have a vested interest in presenting the "full cloud' option as the only option.
Many consumers take comfort in the idea that recordings of their voice are at least improving the technology. But at this point it is highly unlikely you will say something the algorithm can't handle by now.
Meanwhile, as the benefits to lending your voice are ever shrinking, the risks of abuse are only growing.
To learn more about the near future risks surrounding 'AI', visit the SHERPA website.
It's time to make it opt-in
For now, Apple is the only company that has taken the public backlash seriously. In response to the revelations they promised to move to an 'opt-in' model, where you can decide if recordings of your voice may be used to improve their service.
While this could be construed as an admission of guilt, it's just as important to see this as an admission that for the large majority of situations the 'good enough' stage has indeed been reached. By now, only gathering data from consumers who opt-in should be more than enough to guarantee a robust operation of these services.
Conclusion
Voice control has matured immensely over the last few years. Any claims that it's "vital" for consumers to keep lending their voice should, at the very least, raise more scrutiny.
Now that AI has reached this 'good enough' stage, it's time to let consumers choose if they want to keep feeding AI systems with their data.
We hope that Candle can help offer consumers more choice by showcasing what a privacy focussed smart home looks like. If you already have a voice assistant, creating your own Candle smart home will allow you to taste what the other end of the privacy spectrum feels like. While you may not be able to search Wikipedia with your voice, the most common use cases (settings timers, change the state of devices) works just fine. As an added bonus you can enjoy the increased security of not having your smart home connected to the internet.
If you've never used a voice assistant before (perhaps the privacy aspects worried you), then Candle's 'cloudless' voice control will feel like you get the best of both worlds.
![]()
Candle's goal is to show a different way forward for the Internet of Things / Smart Information Systems. Researching and creating privacy friendly voice control was made possible with support from the SHERPA consortium.
The SHERPA project, and thus by extension Candle, has received funding from the European Union’s Horizon 2020 research and innovation programme, under grant agreement No 786641.
Share this article
These are privacy friendly sharing buttons; no code from these companies has been loaded into this page